编码是每个脚本人、程序员最常见的困惑之一(中文用户尤其常遇),在 AutoHotkey 也不例外。这里一起说说在 AutoHotkey 中可能遇到的编码问题,以及可以避免这些问题的方法。
在 AutoHotkey 中谈到编码时可能在三种情况中:
脚本文件编码
首先请阅读帮助中相关内容:脚本文件代码页。这里说明了解释器(AutoHotkey.exe)加载脚本时选择编码的优先级顺序:
- 若脚本文件开头为字节顺序标记(BOM),则据其选择相应的编码(UTF-8 BOM 或 UTF-16 BOM);
- 若解释器命令行中包含了 /CPn 选项,则使用 n 指定的编码;
- 其他情况下,则使用系统默认代码页(一般简单称为 ANSI 编码)。
一般情况下建议脚本文件使用 ANSI 或 UTF-8 BOM(注意必须加上 BOM)编码,这样一般情况下脚本文件都能正常加载,但下列两种情况中必须使用 UTF-8 BOM 编码,否则脚本加载或执行时会出问题:
- 脚本文件中包含多种非 ANSI 编码字符集的字符,如同时包含简体中文和俄文;
- 脚本可能在不同默认代码页的系统中执行,例如在简体中文系统和日文系统;
对于简体中文 Windows 系统,默认代码页为 CP936(也可以认为是 GB2312、GBK 或 GB18030),这是种双字节字符集(缩写 DBCS,是多字节字符集即 MBCS 的一种,与单字节字符集 SBCS 相对;典型的多字节字符集如汉字,而单字节字符集常见于欧洲语言)。对于上面的第二种情况,如果脚本只包含 ANSI 字符,那么应该也能正常执行,不过中文用户脚本中不包含汉字的可能性有多大呢?
注:AutoHotkey Basic 默认脚本编码为 ANSI;对于 AutoHotkey_L,在 1.1.08.00 版本之前,ANSI 构建(build)默认脚本编码为 ANSI,但 Unicode 构建默认编码为 UTF-8,为了减少混乱,该版本之后脚本默认编码都使用 ANSI(所以 UTF-8 编码的脚本必须包含 BOM 头部才能被正确识别)。
SciTE4AutoHotkey 中在工具中设置默认代码页为 UTF-8 时创建的 UTF-8 脚本不含 BOM:
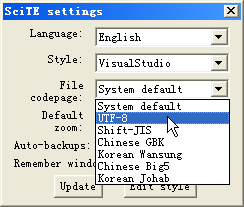
此时【File】【Encoding】中显示的编码并不会改变,因为上面的默认代码设置是通过脚本实现的,因此若要使用 UTF-8 BOM 编码,则每次创建脚本时都需要手动在该菜单下选择【UTF-8 with BOM】,幸运的是中文论坛已经有人解决了该问题(SciTE4AutoHotkey 新建编码为 UTF-8、SciTE4AutoHotkey 新建文件默认编码 UTF-8 with BOM:补充后一方法,待验证)。对于其他编辑器(如 Notepad++),必须注意选择 UTF-8 编码时是否包含了 BOM(不同的编辑器有所区别),例如记事本,另存时编码中的 UTF-8 是包含了 BOM 的。
脚本编码错误一般具体表现为:脚本加载时出现错误或执行时字符串出现问题(如 MsgBox 显示乱码),因为无效的或不存在于原生代码页中的字符会被替换为占位符:ANSI’?‘或 Unicode‘�’。
基于上述的说明,推荐脚本文件编码统一使用 UTF-8 BOM。
文件编码
文件编码是指在读取和写入文件(文件 I/O)时使用的编码。FileEncoding 可以设置默认编码(A_FileEncoding 包含了脚本当前的默认编码设置),它会被用于 FileRead、FileReadLine、FileAppend、FileOpen 和文件读取循环,不过其中一些命令(函数)中可以使用编码参数覆盖该默认设置。
注意下面两点:
- 在读取文件时,若文件头部包含 BOM,则优先使用该标记指示的编码;
- 如果当前命令中未指定编码参数,之前也未设置默认编码,则使用系统默认编码。
INI 文件编码
IniRead 和 IniWrite 总是使用 UTF-16 或系统默认代码页,即除了 UTF-16 编码(通过 BOM 判断)外,其他所有情况都被视为系统默认编码。
原理: IniRead 和 IniWrite 依靠外部函数 GetPrivateProfileString 和 WritePrivateProfileString 来读取和写入值,这些函数仅支持 UTF-16 编码的 Unicode 文件,其他所有文件都被认为使用系统默认代码页。
对于 IniRead 支持的 UTF-16 编码,需注意下面几点:
- 实际仅支持 UTF-16 LE BOM 一种形式,其他可能出问题;
- 在 ANSI 构建中也支持 UTF-16 LE BOM 编码的 INI 文件;
- 当 IniWrite 的目标文件不存在时,ANSI 构建使用系统默认编码创建文件,而 Unicode 构建使用 UTF-16 LE BOM。 所以,如果希望使用指定编码的 INI 文件,则需先使用 FileAppend 并指定编码创建文件。
下图是 Notepad2 中编码设置界面,INI 文件编码必须选择 ANSI(936) 或 Unicode (UTF-16 LE BOM) 脚本才能正常读取和写入:
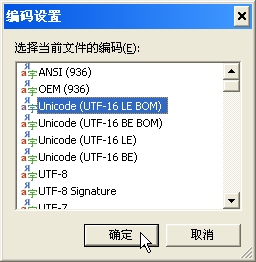
建议脚本的 INI 文件统一使用 UTF-16 LE BOM 编码,以避免脚本在不同系统中运行可能遇到的潜在问题。小头(Little endian)、大头(Big endian)的更多相关知识请参阅:字符编解码的故事(ASCII,ANSI,Unicode,Utf-8区别)、字符编码笔记:ASCII,Unicode和UTF-8
字符串编码
这部分属于进阶内容,相对于前面的内容有较高难度,多实践是理解的关键。
字符串编码是指内存中存储字符时使用的编码,这种编码被称为可执行程序的原生编码,相关帮助内容请参阅 Unicode 与 ANSI 两种构建的比较。简而言之,字符串编码与构建有关,Unicode 构建使用 UTF-16 LE 编码,而 ANSI 构建使用系统默认编码,AutoHotkey Basic 与 ANSI 构建相同。各分支比较的相关说明请参阅选择哪个分支?。
编码转换
通常我们无需关心字符串编码,例如赋值或显示时如果需要转换都会自动进行, 但通过一些高级方法操作字符串则必须考虑,例如在 DllCall、PostMessage/SendMessage、NumPut/NumGet、Capacity 和 StrPut/StrGet 中处理字符串时。
此时一般操作过程为:首先确定原生编码(通过 A_IsUnicode),然后计算目标字符串的大小。例如:
; 获取汉字的 GBK 编码,适用于 AutoHotkey_L 中两种构建。
SetFormat, integer, H ; 让最后获取的编码为十六进制格式。
Char := "中"
; 因不同构建原生编码不同,所以需分别处理:
If A_IsUnicode
{
VarSetCapacity(GBKChar, 3) ; 一个汉字的 GBK 编码占用两个字节,加上字符串截止符。
StrPut(Char, &GBKChar, "CP936") ; 对于简体中文系统,编码参数中使用 CP0 亦可;这里的 GBKChar 为二进制变量,无法通过常规赋值。
}
else
{
GBKChar := Char
}
GBKCode := (NumGet(GBKChar, 0, "UChar") << 8) + NumGet(GBKChar, 1, "UChar")
MsgBox, % GBKCode ; 显示“中”的 GBK 编码为“D6D0”(这里显示为“0xD6D0”)上面获取编码时为什么需要那么复杂?下面这样不行吗?
GBKCode := NumGet(GBKChar, 0, "UInt") ; 这里获取到的编码将为“0xD0D6”。可以发现 GBK 编码在内存中存放时使用大头方式(即第一个字节在前,先高位、后低位),在低字节(LChar)与高字节(WChar)(还有低字与高字)的编码问题时经常需要需要注意这种情况。下面这样是可以的(将显示“0xD60xD0”):
GBKCode := NumGet(GBKChar, 0, "UChar") . NumGet(GBKChar, 1, "UChar")那么使用下面这样呢?
GBKCode := Asc(GBKChar) ; 与上面的示例不同,此处的 GBKChar 仅指中文字符。Asc() 可以获取首个字符的编码,但在 ANSI 构建中的原生编码为系统默认编码,所以一个字符占用一个字节(双字节字符集编码中两个编码的字符实际上被视为两个独立单元),所以显示“0xD6”;而 Unicode 构建中原生编码为 UTF-16 LE(由于在内存中,所以无需字节顺序标记),所以这里使用该方式获取字符编码即小头方式,所以显示“0xD0D6”。
刚才的例子看了可能困惑多于收获,为了让大家掌握字符串编码转换的要领,接着再看另一个例子(这次是解疑):
SetFormat, integer, H
NativeString := "中"
StrCap := StrPut(NativeString, "CP65001")
VarSetCapacity(UTF8String, StrCap)
StrPut(NativeString, &UTF8String, "CP65001")
Loop, % StrCap - 1 ; StrPut 返回的长度中包含末尾的字符串截止符,因此必须减 1。
{
UTF8Codes .= SubStr(NumGet(UTF8String, A_Index - 1, "UChar"), 3) ; 逐字节获取,去除开头的“0x”后连接起来。
}
MsgBox, % UTF8Codes ; 显示“E4B8AD”,前面附加“0x”就变成十六进制了。这里尽管还是转换编码,但许多地方采用适应性更强的方式(如设置变量容量、获取编码和连接字符串的方式),同时还能明白这些具体是怎么来的。不论转换到什么编码,方式还是这一套。所以以后需要转换编码时,无需去记住哪种编码是大头还是小头存储,只需先用个字符测试一次:按顺序逐字节获取并连接起来,和实际比较,不符合时调整顺序就行了。 其中,连接字符串的方式之前使用数值计算(左移),这里则采用字符串连接,个人感觉这种方式更好:
UTF8Codes .= SubStr(NumGet(UTF8String, A_Index - 1, "UChar"), 3)AutoHotkey 中转换编码可以通过 Transform 的 FromCodePage/ToCodePage 两个子命令或 Windows API 进行,不过目前建议使用 StrPut/StrGet 代替。
字符编码常用在与网络交互时,如提交内容到网页或获取网页返回的内容。为了方便,这里把刚才的操作写成函数:
SetFormat, integer, H
String := "汉字"
MsgBox, % Encode(String, "CP65001")
return
Encode(Str, Encoding, Separator = "")
{
StrCap := StrPut(Str, Encoding)
VarSetCapacity(ObjStr, StrCap)
StrPut(Str, &ObjStr, Encoding)
Loop, % StrCap - 1
{
ObjCodes .= Separator . SubStr(NumGet(ObjStr, A_Index - 1, "UChar"), 3)
}
Return, ObjCodes
}这里加了个 Separator 参数,在谷歌中搜索“汉字”时,从网址里可以看到被编码为:
%E6%B1%89%E5%AD%97
而在百度中,则被编码为(这里为 GBK 编码,调用时编码参数为“CP936”):
%BA%BA%D7%D6
所以,此时分隔符中使用百分号就行了。
最后,转换字符串编码时建议在 StrPut/StrGet 的编码参数中尽量不使用“CP0”,而指明具体的编码。因为“CP0”表示系统默认编码,与系统有关。不使用 Asc 也是因为它依赖于 AutoHotkey_L 构建,尽管在特定构建中它可能比较简单。
小结
多实践、多小结以加深理解,使用推荐的编码方式可以减少实际中可能遇到的编码问题。此外,需注意下面几点:
- “一个汉字占用两个字节”的说法不严谨,应具体指明字符集(charset)和编码(encoding);
- 在 Basic 版本中,Asc(char) 总是将一个字节视为一个字符,即完全等同于:
- NumGet(char, 0, "UChar")
但 AutoHotkey_L 中则能正确处理字符,Asc(char) 总是能获取一个字符的编码(包括单字节字符集和双字节字符集中的字符),因为它是依据原生编码的方式获取的(不过二进制变量通常必须手工处理才能获取正确编码)。
- NumGet(char, 0, "UChar")